Svelte
Core
『通过静态编译减少框架运行时的代码量』
vue 和 react 这类传统的框架,都必须引入运行时 (runtime) 代码,用于虚拟dom、diff 算法。Svelted完全溶入JavaScript,应用所有需要的运行时代码都包含在bundle.js里面了,除了引入这个组件本身,你不需要再额外引入一个运行代码。
优势
No Runtime —— 无运行时代码
React 和 Vue 都是基于运行时的框架,当用户在你的页面进行各种操作改变组件的状态时,框架的运行时会根据新的组件状态(state)计算(diff)出哪些DOM节点需要被更新,从而更新视图。
这就意味着,框架本身所依赖的代码也会被打包到最终的构建产物中。这就不可避免增加了打包后的体积
Less-Code ——写更少的代码
在写svelte组件时,你就会发现,和 Vue 或 React 相比只需要更少的代码。开发者的梦想之一,就是敲更少的代码。因为更少的代码量,往往意味着有更好的语义性,也有更少的几率写出bug。
const [count, setCount] = useState(0);
function increment() {
setCount(count + 1);
}let count = 0;
function increment() {
count += 1;
}Hight-Performance ——高性能
Virtual DOM 有时候会做很多无用功,这体现在很多组件会被“无缘无故”进行重渲染(re-render)
比如说,下面的例子中,React 为了更新掉message 对应的DOM 节点,需要做n多次遍历,才能找到具体要更新哪些节点。

为了解决这个问题,React 提供pureComponent,shouldComponentUpdate,useMemo,useCallback让开发者来操心哪些subtree是需要重新渲染的,哪些是不需要重新渲染的。究其本质,是因为 React 采用 jsx 语法过于灵活,不理解开发者写出代码所代表的意义,没有办法做出优化。
所以,React 为了解决这个问题,在 v16.0 带来了全新的 Fiber 架构,Fiber 思路是不减少渲染工作量,把渲染工作拆分成小任务。渲染过程中,留出时间来处理用户响应,让用户感觉起来变快了。这样会带来额外的问题,不得不加载额外的代码,用于处理复杂的运行时调度工作
Templates语法
Template模板是一种非常有约束的语言,你只能以某种方式去编写模板
更加严格和具有语义性,可以在编译的过程中就进行优化操作
JSX语法
jsx 具有 JavaScript 的完整表现力,非常具有表现力,可以构建非常复杂的组件。但是灵活的语法,也意味着引擎难以理解,无法预判开发者的用户意图,从而难以优化性能。
Svelte 记录脏数据的方式: 位掩码(bitMask)
Svelte使用位掩码(bitMask) 的技术来跟踪哪些值是脏的,即自组件最后一次更新以来,哪些数据发生了哪些更改。
位掩码是一种将多个布尔值存储在单个整数中的技术,一个比特位存放一个数据是否变化,一般1表示脏数据,0表示是干净数据。
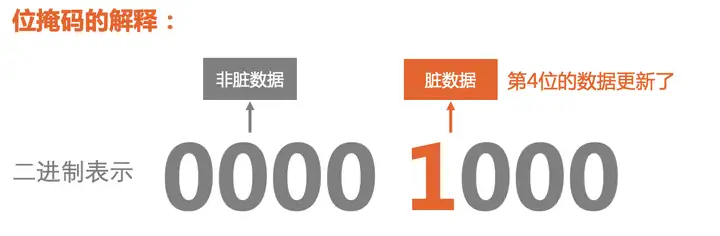
用大白话来讲,你有A、B、C、D 四个值,那么二进制0000 0001表示第一个值A发生了改变,0000 0010表示第二个值B发生了改变,0000 0100表示第三个值C发生了改变,0000 1000表示第四个D发生了改变。
这种表示法,可以最大程度的利用空间。为啥这么说呢?
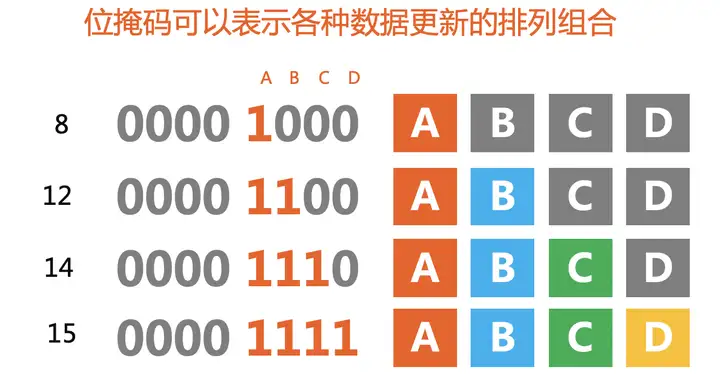
JS 的二进制有31位限制,number 类型最长是32位,减去1位用来存放符号。也就是说,如果 Svelte 采用二进制位存储的方法,那么只能存 31个数据。
但肯定不能这样,对吧?
Svelte 采用数组来存放,数组中一项是二进制31位的比特位。假如超出31个数据了,超出的部分放到数组中的下一项。
这个数组就是component.$.dirty数组,二进制的1位表示该对应的数据发生了变化,是脏数据,需要更新;二进制的0位表示该对应的数据没有发生变化,是干净的
component.$.dirty
我们模拟一个 Svelte 组件,这个 Svelte 组件会修改33个数据。
我们打印出每一次make_dirty之后的component.$.dirty, 为了方便演示,转化为二进制打印出来,如下面所示:

上面数组中的每一项中的每一个比特位,如果是1,则代表着该数据是否是脏数据。如果是脏数据,则意味着更新。
- 第一行
["0000000000000000000000000000001", "0000000000000000000000000000000"], 表示第一个数据脏了,需要更新第一个数据对应的dom节点 - 第二行
["0000000000000000000000000000011", "0000000000000000000000000000000"], 表示第一个、第二个数据都脏了,需要更新第一个,第二个数据对应的dom节点。 - ……

4是一个常量,转变为二进制是0000 0100, 第三位是1。那么也就是,只有dirty[0]的二进制的第三位也是1时, 表达式才会返回真。 换句话来说,只有第三个数据是脏数据,才会走入到这个if判断中,执行set_data(t5, ctx[2]), 更新t5这个 DOM 节点
它们其实是保存了这33个变量 和 真实DOM 节点之间的对应关系,哪些变量脏了,Svelte 会走入不同的if体内直接更新对应的DOM节点,而不需要复杂 Virtual DOM DIFF 算出更新哪些DOM节点;
这 30多行代码,是Svelte 编译了我们写的Svelte 组件之后的产物,在Svelte 编译时,就已经分析好了,数据 和 DOM 节点之间的对应关系,在数据发生变化时,可以非常高效的来更新DOM节点。
Svelte 采用了比特位的存储方式,解决了保存脏数据会消耗内存的问题。
下面是非常简单的一个 Svelte 组件,点击<button>会触发onClick事件,从而改变name 变量。

上面代码背后的整体流程如下图所示,我们一步一步来看:
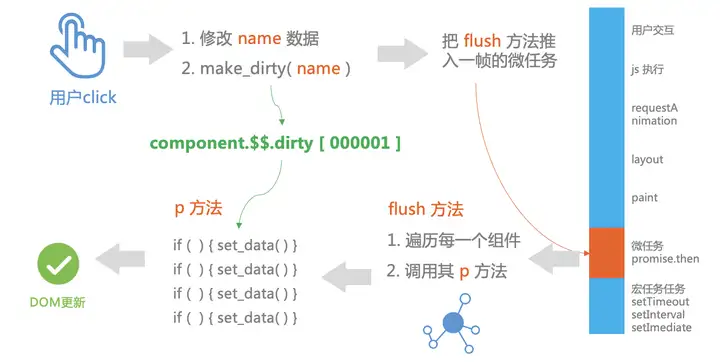
第一步,Svelte 会编译我们的代码,下图中左边是我们的源码,右边是 Svelte 编译生成的。Svelte 在编译过程中发现,『咦,这里有一行代码 name 被重新赋值了,我要插入一条make_dirty的调用』,于是当我们改写 name 变量的时候,就会调用make_dirty方法把 name 记为脏数据。

第二步,我们来看make_diry方法究竟做了什么事情:
- 把对应数据的二进制改为1
- 把对应组件记为脏组件,推入到 dirty_components 数组中
- 调用
schedule_update()方法把flush方法推入到一帧中的微任务阶段执行。因为这样既可以做频繁更新 的截流,又避免了阻塞一帧中的 layout, repaint 阶段的渲染。

schedule_update 方法其实就是一个promise.then(),

一帧大概有 16ms, 大概会经历 layout, repaint的阶段后,就可以开始执行微任务的回调了。
flush 方法做的事情也比较简单,就是遍历脏组件,依次调用update方法去更新对应的组件。

update方法除了执行一些生命周期的方法外,最核心的一行代码是调用p方法,p方法我们已经在上文中介绍过很熟悉了。

p 方法的本质就是走入到不同的if 判断里面,调用set_data原生的 javascript 方法更新对应的 DOM节点。

至此,我们的页面的DOM节点就已经更新好了。
Svelte 在处理子节点列表的时候,还是有优化的算法在的。比如说[a,b,c,d] 变成 [d, a, b, c] ,但是只是非常简单的优化,简单来说,是比较节点移动距离的绝对值,绝对值最小的节点被移动。
所以,严格意义上来说,Svelte 并不是100%无运行时,还是会引入额外的算法逻辑,只是量很少罢了。
劣势
-
没有成熟的UI库
-
Svelte 原生不支持预处理器,比如说
less/scss,需要自己单独的配置 webpack loader -
Svelte 原生脚手架没有目录划分